It is a process in which natural language processing and machine learning process raw text data, discovers insights, performs sentiment analysis, and identifies the subject. These insights are used to classify the raw text according to predetermined categories.

Text classifier models, along with NLP, have proven to be an efficient way to process raw textual data and extract the desired information. Text classification is increasingly becoming an important part of business’ automation processes as it provides easy access to insights from raw text.
Data Classification Market Trends
Source: MRFR Research
Phases of Text Classification
As an example, let’s consider a company that would like to gauge consumer interest for their different product categories. For this, let’s say they want to analyze their chat support data to understand their customer’s feedback and interest for their different products:
Phases of Text Classification
Phases of Text Classification
Extract relevant data from data sources like web pages, data lakes, databases, etc.
Text parsing, cleaning and extracting/retrieving useful information/insights from corpus.
Using NLP techniques such as dependency parsing, and named-entity recognition to analyze textual data, feature engineering, dimensionality reduction, etc.
Map words or phrases to a corresponding vector of real numbers for further processing.
Depending on business problem, relevant machine learning model is trained on the word vectors generated above.
This trained model can now automate the business process by predicting the category of new data.
QASource's Text Classification Expertise
Supervised Text Classification
Classifier models such as logistic regression, SVM, and Decision Tree Classifier can be used based on data analysis for Supervised Text Classification.
Unsupervised Text Classification
Clustering models such as K-means, LDA, GMM can be used based on data analysis for Unsupervised Text Classification.
Classification Using Language Models
Trained language models such as BERT or any domain-specific trained language model can be utilized to solve specific domain based problems.
Testing of Text Classification Models
The performance of text classification models depends on the quality of training data, model selection,
and the test data being used. Some of the common metrics used for testing Text Classifiers models are:

Confusion Matrix
Provides summary of prediction results of a classifier model. The number of correct and incorrect predictions are summarized with count values and broken down by each class.
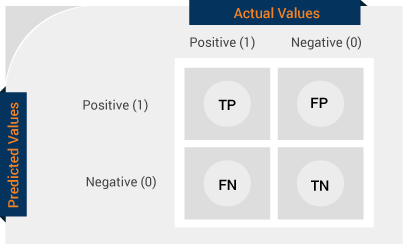
Precision and Recall
Precision is the fraction of relevant instances among the retrieved instances and Recall is the fraction of the total amount of relevant instances that were actually retrieved.
F1 Score
The harmonic mean of Precision and Recall.
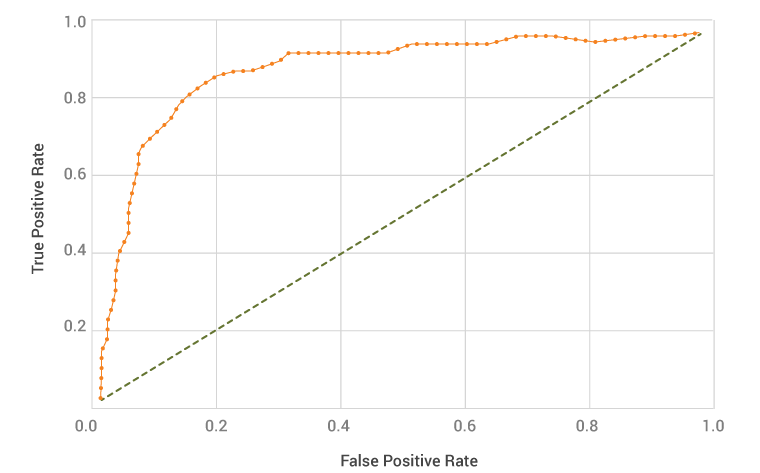
AUC-ROC
ROC is a probability curve and AUC is the degree of separability.
Key Takeaways

- Using NLP, machine learning and text classification processes can be efficiently automated.
- Performance of text classifier will depend on the quality of training data and model selection.
- For domain specific text classification problems, domain specific pre-trained languages model can be used.
- To test text classifier, we need to carefully select test dataset and relevant evaluation metrics should be used to gauge classification model’s performance.
- At QASource, we have extensive experience in developing and testing text classifiers.

Have Suggestions?
We would love to hear your feedback, questions, comments and suggestions. This will help us to make us better and more useful next time.
Share your thoughts and ideas at knowledgecenter@qasource.com

