In today’s hyper-connected digital world, every organization accumulates volumes of data from their customer interactions, chatbots, product reviews, social media, server logs, etc. A huge part of this data is in the form of unstructured text.
Text Analytics incorporates Natural Language Processing and Machine Learning to analyze unstructured text data and turn it into actionable business insights. It evaluates hidden patterns to predict demand for products and services, avoid customer churn, prevent undesired incidents, spot frauds and other risks, and discover unexplored revenue streams.
Businesses can benefit from text analytics and improve the efficiency of business operations. For example, retail companies use text mining and analytics to acquire data from social media platforms. They gain business insights to anticipate the demand & supply and utilize it to analyze customer behavior.
Text Analytic Trends
The global text analytics market is expected to post a CAGR above 20% during 2020-2024, according to the latest market research report.


Phases of Text Analytics

-
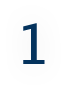
Text Mining: Text parsing, cleaning and extracting/retrieving useful information from the corpus.
-

Text Analytics: Analysis of textual data, feature engineering, dimensionality reduction, etc. Using NLP techniques such as dependency parsing and named-entity recognition to drive deeper insights from text.
-

AI Predictive Model: Feeding the processed data to train AI models, followed by model optimization to achieve the accuracy and best performance.
Common Computational Steps for Text Analysis

|
Tokenization Process of splitting text data (corpus) into smaller chunks or tokens (N-Gram models).
|
Part-of-speech-tagging Process of identifying the part of speech for tokens in data.
|
|
Lemmatization Process of removing inflectional endings of the tokens and converting the token to the base form of a word (lemma).
|
Word vectorization Process of converting words in vectors using techniques like tf–idf.
|
|
Chunking Process of extracting phrases from the unstructured text after POS tagging of tokens.
|
Chunking Process of defining and removing inutile token/sequence of tokens from a chunk.
|
|
Word Embedding Process to make words with similar meaning to have a similar representation. For representation, words are mapped to vectors of real numbers.
|
Named Entity Recognition Process to identify and extract named entities from the corpus to perform categorization based on predefined classes.
|
QASource’s Text Analytics Expertise
At QASource, we have expertise in text analytics with hands-on experience in linguistic, statistical, and machine learning techniques. We cater to an array of text analytics services like text classification, text anomaly detection, and text similarity.
Technologies and Tools Used by QASource
Technologies |
Tools and Techniques |
|---|---|
|
Data Wrangling/Pre-Processing |
Pandas, NumPy, and SciPy |
|
Data Visualization |
Matplotlib, Seaborn, and Tableau |
|
Pre-Trained Language Models |
BERT |
|
Natural Language Processing |
NLTK, spaCy, Bag-of-words, tf–idf, Tokenization, N-Grams, Lemmatization, Stemming, POS tagging, and Noun-Verb phrase, Dependency/Constituency Parsing, Named Entity Recognition, and Word Embedding |
|
Feature Selection/Reduction |
PCA, LDA, Wrapper/Filter Methods, SelectKBest, and Chi2 |
|
Machine Learning |
Scikit-learn and XGBoost |
|
Deep Learning |
Keras, TensorFlow, and Word2vec |
|
Programming Languages |
Python and R |
Key Takeaways

- Using text analytics, organizations can utilize their unstructured text data to gain crucial business insights, discover hidden patterns, predict demand for products and services, and enhance the operations.
- Various Natural Language Processing methods enable you to retrieve information from the text which may be fed AI models for training.
- QASource’s extensive experience in Text Analytics, Natural Language Processing, and AI can help organizations to gain business intelligence, automate business processes, and improve decision making.

Have Suggestions?
We would love to hear your feedback, questions, comments and suggestions. This will help us to make us better and more useful next time.
Share your thoughts and ideas at knowledgecenter@qasource.com


